
在過去的一年里,機器學習炙手可熱。機器學習的“突然”降臨,并不單純因為廉價的云環境和更強有力的GPU硬件。也是因為開放源碼框架的爆炸式增長,這些框架將機器學習中難的部分抽象出來,并將這項技術提供給更廣大范圍的開發者。
這里有十來個新鮮出爐的機器學習框架,既有初次露面的,也有重新修改過的。這些工具被大眾所注意,或是因為其出處,或是因為以新穎的簡單方法處理問題,或是解決了機器學習中的某個特定難題,或者是上述的所有原因。
Apache Spark 為人所知的是它是Hadoop家族的一員,但是這個內存數據處理框架卻是脫胎于Hadoop之外,也正在Hadoop生態系統以外為自己獲得了名聲。Hadoop 已經成為可供使用的機器學習工具,這得益于其不斷增長的算法庫,這些算法可以高速度應用于內存中的數據。
早期版本的Spark 增強了對MLib的支持,MLib是主要面向數學和統計用戶的平臺,它允許 通過持久化管道特性將Spark機器學習工作掛起和恢復。2016年發布的Spark2.0,對Tungsten高速內存管理系統和新的DataFrames流媒體API 進行了改進,這兩點都會提升機器學習應用的性能。
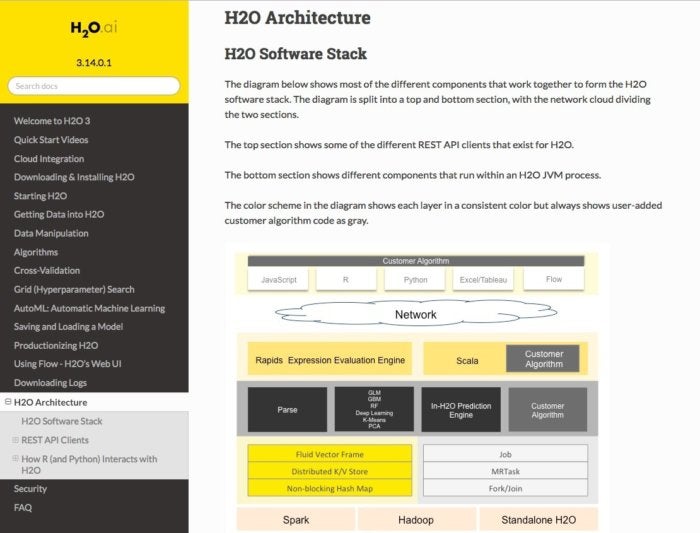
H2O,現在已經發展到第三版,可以提供通過普通開發環境(Python, Java, Scala, R)、大數據系統(Hadoop, Spark)以及數據源(HDFS, S3, SQL, NoSQL)訪問機器學習算法的途徑。H2O是用于數據收集、模型構建以及服務預測的端對端解決方案。例如,可以將模型導出為Java代碼,這樣就可以在很多平臺和環境中進行預測。
H2O可以作為原生Python庫,或者是通過Jupyter Notebook, 或者是 R Studio中的R 語言來工作。這個平臺也包含一個開源的、基于web的、在H2O中稱為Flow的環境,它支持在訓練過程中與數據集進行交互,而不只是在訓練前或者訓練后。

“深度學習”框架增強了重任務類型機器學習的功能,如自然語言處理和圖像識別。Singa是一個Apache的孵化器項目,也是一個開源框架,作用是使在大規模數據集上訓練深度學習模型變得更簡單。
Singa提供了一個簡單的編程模型,用于在機器群集上訓練深度學習網絡,它支持很多普通類型的訓練工作:卷積神經網絡,受限玻爾茲曼機 以及循環神經網絡。 模型可以同步訓練(一個接一個)或者也異步(一起)訓練,也可以允許在在CPU和GPU群集上,很快也會支持FPGA。Singa也通過Apache Zookeeper簡化了群集的設置。
深度學習框架Caffe開發時秉承的理念是“表達、速度和模塊化”,初是源于2013年的機器視覺項目,此后,Caffe還得到擴展吸收了其他的應用,如語音和多媒體。
因為速度放在優先位置 ,所以Caffe完全用C+ +實現,并且支持CUDA加速,而且根據需要可以在CPU和GPU處理間進行切換。分發內容包括免費的用于普通分類任務的開源參考模型,以及其他由Caffe用戶社區創造和分享的模型。
一個新的由Facebook 支持的Caffe迭代版本稱為Caffe2,現在正在開發過程中,即將進行1.0發布。其目標是為了簡化分布式訓練和移動部署,提供對于諸如FPGA等新類型硬件的支持,并且利用先進的如16位浮點數訓練的特性。
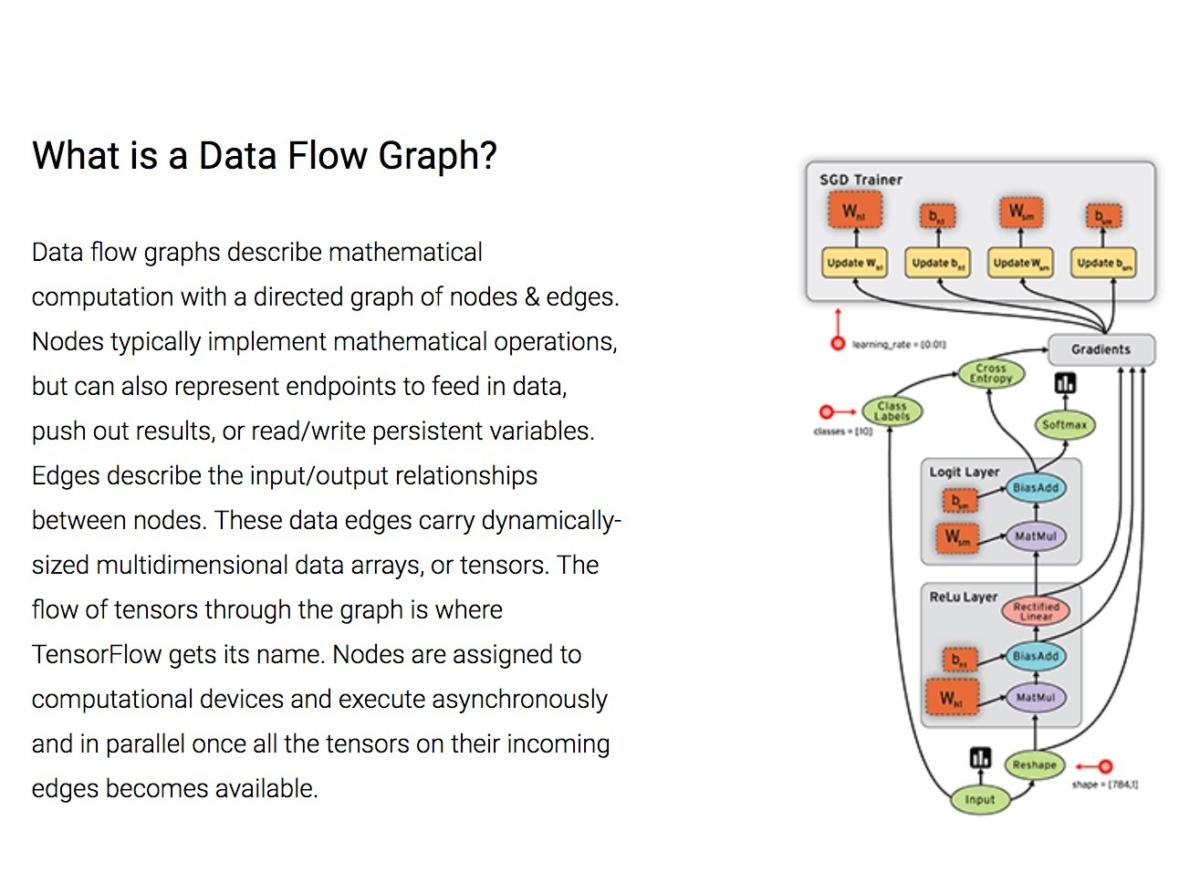
與微軟的DMTK很類似,Google TensorFlow 是一個機器學習框架,旨在跨多個節點進行擴展。 就像Google的 Kubernetes一樣,它是是為了解決內部的問題而設計的,終還是把它作為開源產品發布出來。
TensorFlow實現了所謂的數據流圖,其中的批量數據(“tensors”)可以通過圖描述的一系列算法進行處理。系統中數據的移動稱為“流”-其名也因此得來。這些圖可以通過C++或者Python實現并且可以在CPU和GPU上進行處理。
TensorFlow近來的升級提高了與Python的兼容性,改進了GPU操作,也為TensorFlow能夠運行在更多種類的硬件上打開了方便之門,并且擴展了內置的分類和回歸工具庫。
亞馬遜對云服務的方法遵循一種模式:提供基本的內容,讓核心受眾關注,讓他們在上面構建應用,找出他們真正需要的內容,然后交付給他們。
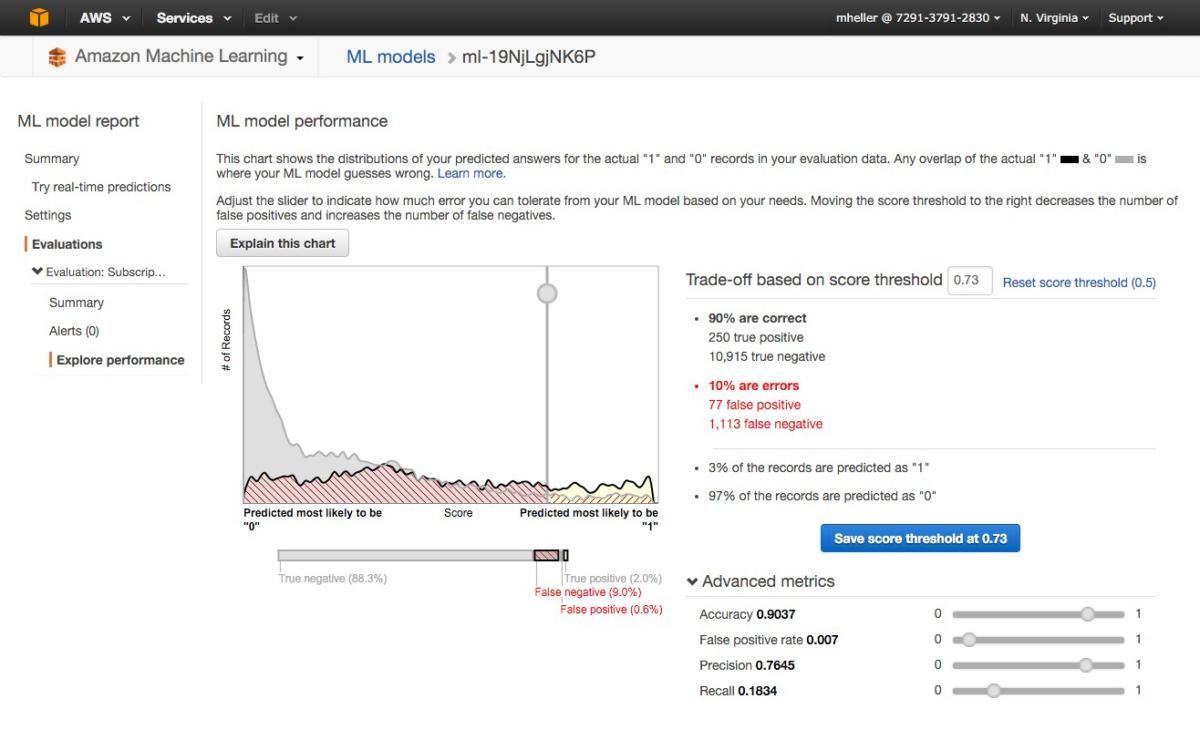
亞馬遜在提供機器學習即服務-亞馬遜機器學習方面也是如此。該服務可以連接到存儲在亞馬遜 S3、Redshift或RDS上的數據,并且在這些數據上運行二進制分類、多級分類或者回歸以構建一個模型。但是,值得注意的是生成的模型不能導入或導出,而訓練模型的數據集不能超過100GB。
但是,亞馬遜機器學習展現了機器學習的實用性,而不只是品。對于那些想要更進一步,或者與亞馬遜云保持不那么緊密聯系的人來說,亞馬遜的深度學習機器圖景包含了許多主要的深度學習框架,包括 Caffe2、CNTK、MXNet和TensorFlow。
考慮到執行機器學習所需的大量數據和計算能力,對于機器學習應用云是一種理想環境。微軟已經為Azure配備了自己的即付即用的機器學習服務-Azure ML Studio,提供了按月、按小時和免費的版本。(該公司的HowOldRobot項目就是利用這個系統創立的。)你甚至不需要一個賬戶來就可以試用這項服務;你可以匿名登錄,免費使用Azure ML Studio多8小時。
Azure ML Studio允許用戶創立和訓練模型,然后把這些模型轉成被其他服務所使用的API。免費用戶的每個賬號可以試用多達10GB的模型數據,你也可以連接自己的Azure存儲以獲得更大的模型。有大范圍的算法可供使用,這要感謝微軟和第三方。
近來的改進包括通過Azure批處理服務、更好的部署管理控制和詳細的web服務使用統計,對訓練任務進行了批量管理。

在機器學習問題中投入更多的機器,會取得更好的效果-但是開發在大量計算機都能運行良好的機器學習應用卻是挺傷腦筋的事。
微軟的DMTK(分布式機器學習工具集)框架解決了在系統集群中分布多種機器學習任務的問題。
DMTK被認為是一個框架而不是一個完全成熟、隨去隨用的解決方案,因此包含算法的數量是很小的。然而,你還是會找到一些關鍵的機器學習庫,例如梯度增強框架(LightGBM),以及對于一些像Torch和Theano這樣深度學習框架的支持。
DMTK的設計使用戶可以利用有限的資源構建大的群集。例如,群集中的每個節點都會有本地緩存,從而減少了與中央服務器節點的通信流量,該節點為任務提供參數。
在發布DMTK之后,微軟又推出了另一款機器學習工具集,即計算網絡工具包,簡稱CNTK。
CNTK與Google TensorFlow類似,它允許用戶通過一個有向圖來創建神經網絡。微軟也認為CNTK可以與諸如Caffe、Theano和 Torch這樣的項目相媲美,-此外CNTK還能通過利用多CPU和GPU進行并行處理而獲得更快的速度。微軟聲稱在Azure上的GPU群集上運行CNTK,可以將為Cortana的語音識別訓練速度提高一個數量級。
新版的CNTK 2.0通過提高精確性提高了TensorFlow的熱度,添加了一個Java API,用于Spark兼容性,并支持kera框架(通常用于TensorFlow)的代碼。
在Spark占據主流地位之前很久,Mahout就已經開發出來,用于在Hadoop上進行可擴展機器學習。但經過一段長時間的相對沉默之后,Mahout又重新煥發了活力,例如一個用于數學的新環境,稱為Samsara,允許多種算法可以跨越分布式Spark群集上運行。并且支持CPU和GPU運行。
Mahout框架長期以來一直與Hadoop綁定,但它的許多算法也可以在Hadoop之外運行。這對于那些終遷移到Hadoop的獨立應用或者是從Hadoop中剝離出來成為單獨的應用都很有用。
[Veles]https://velesnet.ml/)是一個用于深度學習應用的分布式平臺,就像TensorFlow和DMTK一樣,它是用C++編寫的,盡管它使用Python來執行節點之間的自動化和協調。在被傳輸進群集之前,要對數據集分析并且進行自動的歸一化,然后調用REST API來即刻使用已訓練的模型(假定你的硬件滿足這項任務的需要)
Veles不僅僅是使用Python作為粘合代碼,因為基于Python的Jupyter Notebook 可以用來可視化和發布由一個Veles集群產生的結果。Samsung希望,通過將Veles 開源將會刺激進一步的開發,作為通往Windows和MacOS的途徑。
作為一個基于C++的機器學習庫,mlpack初產生于2011年,按照庫的創立者想法,設計mlpack是為了“可擴展性,速度和易于使用。”mlpack既可以通過由若干行命令行可執行程序組成的“黑盒”進行操作,也可以利用C++ API來完成復雜的工作。
mlpack的第二版包含了許多新的算法,以及現有算法的重構,以提高它們的速度或使它們瘦身。例如,它舍棄了Boost庫的隨機數生成器,轉而采用C++ 11的原生隨機數功能。
mlpack的一個痼疾是缺少對于C++以為語言的支持。這就意味著其他語言的用戶需要第三方庫的支持,如這樣的一個Pyhton庫。還有完成了一些工作來增加對MATLAB的支持,但是像mlpack這樣的項目,在機器學習的主要環境中直接發揮作用時,往往會獲得更大的應用。
Nervana,一家建立自己的深度學習硬件和軟件平臺的公司(現在是英特爾的一部分),已經提供了一個名為“Neon”的深度學習的框架,它是一個開源項目。Neon使用可插拔的模塊,以實現在CPU、GPU或者Nervana自己開發的芯片上完成繁重的任務。
Neon主要是用Python編寫,也有一部分是用C++和匯編以提高速度。這使得該框架可以為使用Python或者其他任何與Python綁定框架進行數據科學工作的人所用。
許多標準的深度學習模型,如LSTM、AlexNet和GoogLeNet,都可以作為Neon的預訓練模型。新版本Neon 2.0,增加了英特爾數學內核庫來提高CPU的性能。
另一個相對近期的產品——Marvin神經網絡框架,是普林斯頓視覺集團的產物。Marvin“生來就是被黑的”,正如其創建者在該項目文檔中解釋的那樣,該項目只依賴于一些用C++編寫的文件和CUDA GPU框架。雖然該項目的代碼很少,但是還是提供了大量的預訓練模型,這些模型可以像項目本身代碼一樣,能夠在合適的場合復用或者根據用戶的需要共享。
本站文章版權歸原作者及原出處所有 。內容為作者個人觀點, 并不代表本站贊同其觀點和對其真實性負責,本站只提供參考并不構成任何投資及應用建議。本站是一個個人學習交流的平臺,網站上部分文章為轉載,并不用于任何商業目的,我們已經盡可能的對作者和來源進行了通告,但是能力有限或疏忽,造成漏登,請及時聯系我們,我們將根據著作權人的要求,立即更正或者刪除有關內容。本站擁有對此聲明的最終解釋權。

