
今年的雙11再次刷新了記錄——支付成功峰值達25.6萬筆/秒、實時數據處理峰值4.72億條/秒。 面對較去年增幅100%的數據洪峰,流計算技術可謂功不可沒。今天,我們將揭開阿里流計算技術的神秘面紗。

雙11剛剛拉下帷幕,激動的心還停留在那一刻:
當秒針剛跨過11號零點的一瞬間,來自線上線下的千萬剁手黨在時間涌入了這場年度大趴——從進入會場到點擊詳情頁,再到下單付款一氣呵成。
前臺在大家狂歡的同時,后臺數據流量也正以突破歷史新高的洪峰形式急劇涌入:
支付成功峰值達 25.6 萬筆/秒
實時數據處理峰值 4.72億條/秒
而作為實時數據處理任務中為重要的集團數據公共層(保障著業務的實時數據、媒體大屏等核心任務),在當天的總數據處理峰值更是創歷史新高達1.8億/秒! 想象下,1秒鐘時間內千萬人涌入雙11會場的同時,依然應對自如。
流計算的產生即來源于數據加工時效性的嚴苛需求:
由于數據的業務價值會隨著時間的流失而迅速降低,因此在數據發生后必須盡快對其進行計算和處理,從而能夠通過數據時間掌握業務情況。今年雙11的流計算也面臨著一場實時數據洪峰的考驗。
首先來展示今年(2017年)較去年(2016年)數據洪峰峰值的比較:
2016年:支付成功峰值12萬筆/秒,總數據處理峰值9300萬/秒
2017年:支付成功峰值25.6 萬筆/秒,實時數據處理峰值 4.72億條/秒,阿里巴巴集團數據公共層總數據處理峰值1.8億/秒
在今年雙11流量峰值翻翻的情況下,依然穩固做到實時數據更新頻率:從第1秒千萬剁手黨涌入到下單付款,到完成實時計算投放至媒體大屏全路徑,秒級響應。面對越發抬升的流量面前,實時數據卻越來越快、越來越準。在hold住數據洪峰的背后,是阿里巴巴流計算技術的全面升級。
流計算應用場景
數據技術及產品部定位于阿里數據中臺,除了離線數據外,其產出的實時數據也服務于集團內多個數據場景。包括今年(其實也是以往的任何一年)雙11媒體大屏實時數據、面向商家的生意參謀實時數據,以及面向內部高管與小二的各種直播廳產品,覆蓋整個阿里巴巴集團大數據事業部。
同時隨著業務的不斷發展壯大,到目前為止,日常實時處理峰值超4000萬/s,每天總處理記錄數已經達到萬億級別,總處理數據量也達到PB級別。
面對海量數據的實時數據我們成功做到了數據延遲控制在秒級范圍內,在計算準確率上,已實現了高精準、0誤差,達到精確處理。比如:今年的雙11當天,雙十一媒體屏條記錄從交易表經過流計算計算處理到達媒體大屏秒級響應。
數據中臺流計算實踐中的數據鏈路
在經過近幾年大促數據洪峰的經歷后,使得我們的流計算團隊在引擎選擇,優化性能以及開發流計算平臺上都積累了豐富的經驗。我們也形成了穩定高效的數據鏈路架構,下圖是整個數據鏈路示意圖:
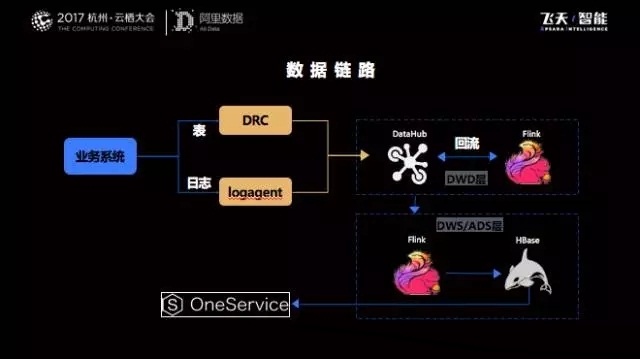
業務數據的來源非常多,分別通過兩個工具(DRC與中間件的logagent)實時獲取增量數據,并且同步到DataHub(一種PubSub的服務)。
實時計算引擎Flink作業通過訂閱這些增量數據進行實時處理,并且在經過ETL處理后把明細層再次回流到Datahub,所有的業務方都會去定義實時的數據進行多維度的聚合,匯總后的數據放在分布式數據庫或者關系型數據庫中(Hbase、Mysql),并通過公共的數據服務層產品(One Service)對外提供實時數據服務。
近一年,我們在計算引擎和計算優化方面做了很多工作,實現了計算能力、開發效率的提升。
計算引擎升級及優化
在2017年,我們在實時計算架構上進行了全面的升級,從Storm遷移到Blink,并且在新技術架構上進行了非常多的優化,實時峰值處理能力提高了2倍以上,平穩的處理能力更是提高5倍以上:
優化狀態管理
實時計算過程中會產生大量的state,以前是存儲在HBase,現在會存儲在RocksDB中,本地存儲減少了網絡開銷,能夠大幅提高性能,可以滿足細粒度的數據統計(現在key的個數可以提升到億級別了,是不是棒棒噠~)
優化checkpoint(快照/檢查點)和compaction(合并)
state會隨著時間的流轉,會越來越大,如果每次都做全量checkpoint的話,對網絡和磁盤的壓力非常大;所以針對數據統計的場景,通過優化rocksdb的配置,使用增量checkpoint等手段,可以大幅降低網絡傳輸和磁盤讀寫。
異步Sink
把sink改成異步的形式,可以大限度提高CPU利用率,可以大幅提供TPS。
抽象公共組件
除了引擎層面的優化,數據中臺也針對性地基于Blink開發了自己的聚合組件(目前所有實時公共層線上任務都是通過該組件實現)。該組件提供了數據統計中常用的功能,把拓撲結構和業務邏輯抽象成了一個json文件。這樣只需要在json文件中通過參數來控制,實現開發配置化,大幅降低了開發門檻,縮短開發周期——再來舉個栗子:之前我們來做開發工作量為10人/日,現在因為組件化已讓工作量降低為0.5人/日,無論對需求方還是開發方來講都是好消息,同時歸一的組件提升了作業性能。
按照上述思路及功能沉淀,終打磨出了流計算開發平臺【赤兔】。
該平臺通過簡單的“托拉拽”形式生成實時任務,不需要寫一行代碼,提供了常規的數據統計組件,并集成元數據管理、報表系統打通等功能。作為支撐集團實時計算業務的團隊,我們在經過歷年雙11的真槍實彈后沉淀的[赤兔平臺]中獨有的功能也成為它獨一無二的亮點:
一、大小維度合并
比如很多的實時統計作業同時需要做天粒度與小時粒度的計算,之前是通過兩個任務分開計算的,聚合組件會把這些任務進行合并,并且中間狀態進行共用,減少網絡傳輸50%以上,同時也會精簡計算邏輯,節省CPU。
二、精簡存儲
對于存儲在RocksDB的Keyvalue,我們設計了一個利用索引的encoding機制,有效地將state存儲減少一半以上,這個優化能有效降低網絡、cpu、磁盤的壓力。
三、高性能排序
排序是實時中非常常見的一個場景, top組件利用內存中PriorityQueue(優先隊列) 和blink中新的MapState feature(中間狀態管理特性),大幅減少序列化次數,性能提高10倍左右。
四、批量傳輸和寫操作
終寫結果表HBase和Datahub時,如果每處理一條記錄都去寫庫的話,就會很大限制我們的吞吐。我們組件通過時間觸發或者記錄數觸發的機制(timer功能),實現批量傳輸和批量寫(mini-batch sink),并且可以根據業務延時要求進行靈活配置,提高任務吞吐的同時,也降低了服務端壓力。
數據保障
對于高優先級應用(每天24小時不間斷服務),需要做到跨機房容災,當某條鏈路出現問題時,能夠秒級切換到其他鏈路,下圖是整個實時公共層的鏈路保障架構圖:
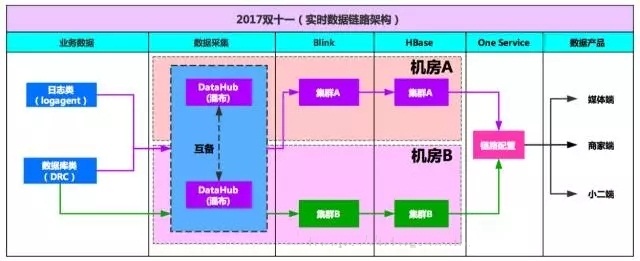
從數據采集、數據同步、數據計算、數據存儲、數據服務,整條鏈路都是獨立的。通過在Oneservice中的動態配置,能夠實現鏈路切換,保障數據服務不終端。
上面內容就是保障今年雙11流量洪峰的流計算技術秘密武器——我們不僅在于創新更希望能沉淀下來復用、優化技術到日常。
隨著流計算的技術外界也在不停更迭,后續基于阿里豐富業務場景下我們還會不斷優化升級流計算技術:
平臺化,服務化,Stream Processing as a service
語義層的統一,Apache Beam,Flink 的Table API,以及終Stream SQL都是非常熱的project
實時智能,時下很火的深度學習或許未來會與流計算碰撞產生火花
實時離線的統一,這個也是很大的趨勢,相較于現在普遍存在的實時一套,離線一套的做法,實時離線的統一也是各大引擎努力想要達到的。
本站文章版權歸原作者及原出處所有 。內容為作者個人觀點, 并不代表本站贊同其觀點和對其真實性負責,本站只提供參考并不構成任何投資及應用建議。本站是一個個人學習交流的平臺,網站上部分文章為轉載,并不用于任何商業目的,我們已經盡可能的對作者和來源進行了通告,但是能力有限或疏忽,造成漏登,請及時聯系我們,我們將根據著作權人的要求,立即更正或者刪除有關內容。本站擁有對此聲明的最終解釋權。

