
Yann LeCun大神曾經(jīng)說過,“對(duì)抗訓(xùn)練是近些年來機(jī)器學(xué)習(xí)領(lǐng)域中炫酷的想法”。沒錯(cuò),對(duì)抗訓(xùn)練已經(jīng)在深度學(xué)習(xí)的圈子里掀起了不小的漣漪。本文將介紹三篇基于Ian Goodfellow開創(chuàng)性工作論文。
筆者曾在一篇博文中簡(jiǎn)單提過Ian Goodfellow的生成對(duì)抗網(wǎng)絡(luò)論文,《九篇深度學(xué)習(xí)好文》。這些網(wǎng)絡(luò)模型的基本思想就是基于兩個(gè)模型:一個(gè)生成模型和一個(gè)判別模型。
判別模型的任務(wù)是判斷一張給定的圖片是真實(shí)的還是經(jīng)過人工修飾。生成器的任務(wù)是模擬生成與圖集中的圖片相似的合成圖片。我們可以把這個(gè)過程看作一種零和游戲。
論文中打了個(gè)比方,生成模型類似“一個(gè)假幣制造團(tuán)伙,試圖生產(chǎn)和使用假幣”,而判別模型類似“金融警察,發(fā)現(xiàn)和查處假幣”。生成器不斷地愚弄判別器,而判別器試圖反抗生成器的愚弄。由于模型訓(xùn)練通過交替優(yōu)化,兩種模型終都能達(dá)到“無法區(qū)分真品和贗品”的程度。
對(duì)抗網(wǎng)絡(luò)的一大用途就是在經(jīng)過充分訓(xùn)練之后,能夠生成以假亂真的圖片。下面是Goodfellow 在2014年發(fā)表的論文中給出的例子。

如圖所示,生成器模擬生成的手寫數(shù)字和人臉圖片非常相似,而模擬CIFAR-10數(shù)據(jù)集生成的圖片則略遜色。
為了改善這一現(xiàn)象,Emily Denton, Soumith Chintala, Arthur Szlam 和 Rob Fergus等人發(fā)表了一篇論文《Deep Generative Image Models using Laplacian Pyramid of Adversarial Networks》。這篇文章的主要貢獻(xiàn)在于提供了一種網(wǎng)絡(luò)模型結(jié)構(gòu),利用這種網(wǎng)絡(luò)生成的高質(zhì)量圖片對(duì)人類評(píng)判者的蒙蔽概率接近40%。
在討論文章細(xì)節(jié)之前,我們先來回顧生成器在GAN模型中發(fā)揮的作用。它需要生成大量復(fù)雜的圖片來迷惑經(jīng)過訓(xùn)練的判別器 —— 乍一看這項(xiàng)任務(wù)并不輕松。該文作者們所采取的方法是用多個(gè)CNN模型以此生成不同尺度的圖片。作者Emily Denton在LAPGANs的講座中說到:
“低分辨率的圖片很容易生成。依照低分辨率的圖片生成另一張分辨率稍高的圖片也不是那么困難。”
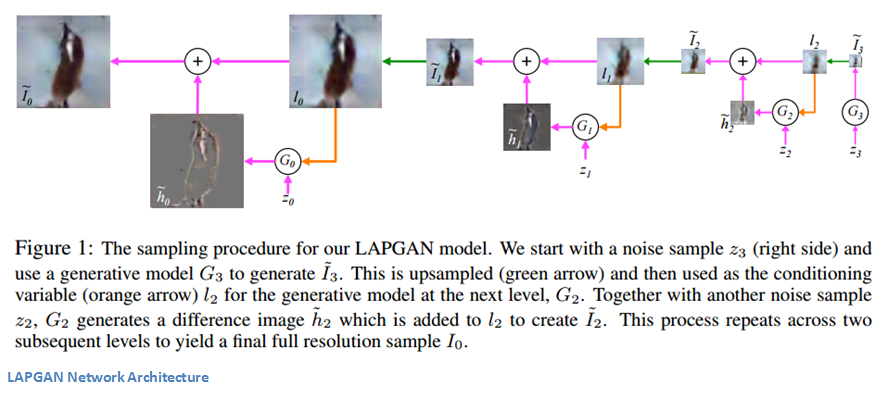
此文采用的方法是構(gòu)造一組生成模型的拉普拉斯金字塔。有些讀者可能還不熟悉,可以參考閱讀這篇文章。基本的思想是金字塔每一層表示了某個(gè)尺度下圖片包含的信息。相當(dāng)于對(duì)原始圖片按尺度做了層級(jí)分解。
一個(gè)簡(jiǎn)單的GAN模型需要輸入和輸出兩部分。生成器按照概率分布輸入一個(gè)噪聲向量,輸出一張圖片。判別器輸入這張圖片(或是訓(xùn)練集中的一張真實(shí)圖片),輸出一個(gè)分?jǐn)?shù),表示該圖片的真實(shí)性。接著,我們來看看條件GAN(CGAN)。它的主體部分與GAN都相同,區(qū)別在于生成器和判別器還需要輸入額外的信息。這種信息類似于某種類別標(biāo)簽或是另一張圖片。
作者們提出了一組卷積網(wǎng)絡(luò)模型,金字塔的每一層都對(duì)應(yīng)一個(gè)卷積網(wǎng)絡(luò)。傳統(tǒng)的GAN結(jié)構(gòu)只用一個(gè)生成器來產(chǎn)生整張圖片,他們采用的方法是用一組CNN產(chǎn)生一系列分辨率逐漸提高的圖片。
每一層都對(duì)應(yīng)獨(dú)立的CNN,并且都基于兩部分訓(xùn)練,一張低分辨率的圖片以及一個(gè)噪聲向量(傳統(tǒng)GAN的輸入只有后者)。這也是CGAN思想的實(shí)踐之處。它的輸出是一張合成圖片,升采樣之后作為金字塔后一級(jí)的輸入。因?yàn)樵诿總€(gè)層級(jí)的生成器能夠利用來自不同分辨率的信息,以便在各個(gè)層級(jí)中創(chuàng)建更細(xì)粒度的輸出,所以此方法是有效的。

這篇論文發(fā)表于去年六月,主要介紹將文字描述轉(zhuǎn)換為圖片的方法。例如,網(wǎng)絡(luò)模型的輸入可以是“一朵粉紅色花瓣的花”,輸出就是包含這些特征的一幅圖片。這項(xiàng)任務(wù)由兩部分組成。一方面通過自然語言處理技術(shù)來分析和理解輸入的文本信息,另一方面是生成準(zhǔn)確和自然的圖片的生成模型。
論文作者認(rèn)為,從文字到圖像的過程比圖像到文字的過程難很多倍(參加Karpathy的論文)。不僅因?yàn)橄袼攸c(diǎn)的數(shù)量非常多,而且不能把整個(gè)任務(wù)拆解為每一步預(yù)測(cè)下一個(gè)詞語(圖像到文字的方式工作)。
論文中所采用的方法是基于由遞歸文本編碼器生成的文本特征來訓(xùn)練一個(gè)GAN模型(詳細(xì)內(nèi)容參考這篇論文)。生成器和判別器在各自的網(wǎng)絡(luò)結(jié)構(gòu)中使用這些特征。這也是GAN連接輸入的文本描述和輸出的合成圖像的橋梁。
我們首先來看生成器。噪聲向量z以及文本編碼是網(wǎng)絡(luò)的輸入。文本編碼是一種封裝輸入描述信息的方式,隨后它被拼接到噪聲向量(參見下圖)。然后用逆卷積層將輸入向量轉(zhuǎn)化為合成圖片。
判別器輸入一張圖片,經(jīng)過一組卷積層(包括 BatchNorm 和 ReLU)。終輸出一個(gè)表示圖片真實(shí)度的分?jǐn)?shù)。
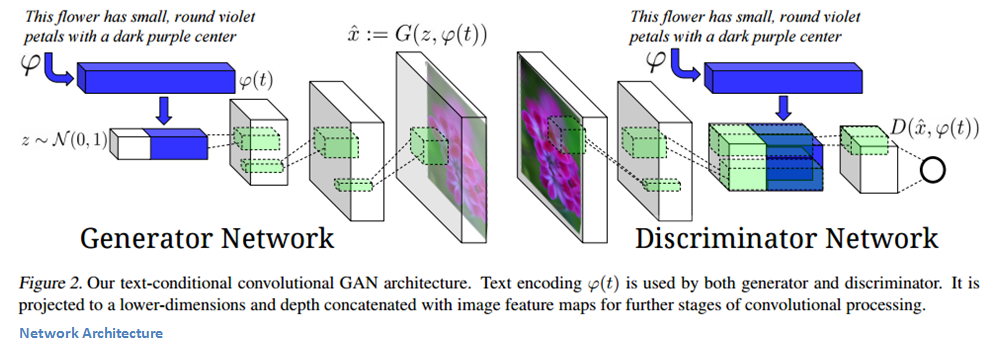
這個(gè)模型有趣的一點(diǎn)是它的訓(xùn)練方式。如果你仔細(xì)考慮需要解決的任務(wù),會(huì)發(fā)現(xiàn)生成器有兩項(xiàng)工作需要完成。一項(xiàng)是生成真實(shí)和偽造的圖片,另一項(xiàng)是要確保生成的圖片與文字描述相關(guān)。同樣,判別器也需要考慮這兩方面的因素,確保偽造圖片或者與描述不匹配的圖片被檢測(cè)到。
為了創(chuàng)建這些通用的模型,作者用三種類型的數(shù)據(jù)進(jìn)行訓(xùn)練:{真實(shí)圖像,正確文本},{假圖像,正確文本},和{真實(shí)圖像,錯(cuò)誤文本}。對(duì)于后一組訓(xùn)練數(shù)據(jù),判別器必須找出與文字描述不匹配的圖像(即使他們看起來很自然)。

作為在此領(lǐng)域進(jìn)行快速創(chuàng)新的證明,Twitter的團(tuán)隊(duì)在不久前發(fā)布了這篇論文。此篇論文中介紹的模型是超分辨率生成對(duì)抗網(wǎng)絡(luò)(SRGAN)。此文的主要貢獻(xiàn)是發(fā)明了一種全新的損失函數(shù)(比普通的MSE更好),使得網(wǎng)絡(luò)模型能夠根據(jù)嚴(yán)重降采樣的圖像恢復(fù)出逼真的紋理和細(xì)節(jié)。
我們先來看看這個(gè)新的損失函數(shù)。這種損失函數(shù)可以分為兩部分:對(duì)抗損失和內(nèi)容損失。從上層角度分析,對(duì)抗損失鼓勵(lì)看起來自然的圖像(它們像是來自數(shù)據(jù)集),內(nèi)容損失確保新的高分辨率圖像具有原始低分辨率圖像的類似特性。
接著我們深入到細(xì)節(jié)。對(duì)同一張圖片,我們分別準(zhǔn)備一個(gè)高分辨率版本和一個(gè)低分辨率版本。接著訓(xùn)練生成器,使根據(jù)低分辨率圖片輸出的合成圖片,盡可能接近高分辨率版本。此輸出被稱為超分辨圖像。然后,訓(xùn)練判別器來區(qū)分這些圖像。
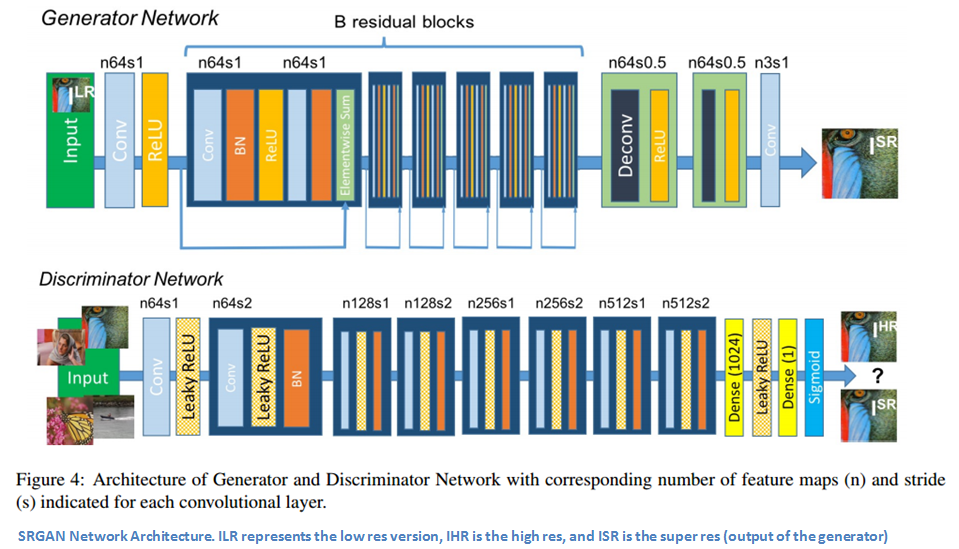
我們?cè)倩氐叫碌膿p失函數(shù)。它實(shí)際上是多個(gè)獨(dú)立損失函數(shù)的加權(quán)和。部分是內(nèi)容損失,這實(shí)際上是新的重建圖像(網(wǎng)絡(luò)輸出)與實(shí)際的高分辨率圖像之間的歐氏距離。按照作者的理解,這樣做的主要目標(biāo)是確保兩圖像的內(nèi)容相似,將它們送入訓(xùn)練好的ConvNet模型后看各自的特征激活情況。
作者定義的另一種主要損失函數(shù)是對(duì)抗損失。這類似于傳統(tǒng)的GAN。它鼓勵(lì)輸出與原始數(shù)據(jù)分布類似的結(jié)果。有了這個(gè)新的損失函數(shù),生成器確保輸出更高分辨率的自然圖像,卻仍然保留與低分辨率圖像類似的像素空間。

GAN采用了大規(guī)模的無監(jiān)督式訓(xùn)練(我們只需要一個(gè)真實(shí)的圖集,不需要標(biāo)注等等信息)。這意味著我們可以利用現(xiàn)在大量的非結(jié)構(gòu)化圖像數(shù)據(jù)。訓(xùn)練結(jié)束后,我們可以使用輸出或中間層作為特征提取器,用于給其它分類器提供特征,它不需要太多的訓(xùn)練數(shù)據(jù)就能達(dá)到不錯(cuò)的精度。
本站文章版權(quán)歸原作者及原出處所有 。內(nèi)容為作者個(gè)人觀點(diǎn), 并不代表本站贊同其觀點(diǎn)和對(duì)其真實(shí)性負(fù)責(zé),本站只提供參考并不構(gòu)成任何投資及應(yīng)用建議。本站是一個(gè)個(gè)人學(xué)習(xí)交流的平臺(tái),網(wǎng)站上部分文章為轉(zhuǎn)載,并不用于任何商業(yè)目的,我們已經(jīng)盡可能的對(duì)作者和來源進(jìn)行了通告,但是能力有限或疏忽,造成漏登,請(qǐng)及時(shí)聯(lián)系我們,我們將根據(jù)著作權(quán)人的要求,立即更正或者刪除有關(guān)內(nèi)容。本站擁有對(duì)此聲明的最終解釋權(quán)。

